dna package
Submodules
dna.dna_averages module
Module containing the HelParAverages class and the command line interface.
- class dna.dna_averages.HelParAverages(input_ser_path, output_csv_path, output_jpg_path, properties=None, **kwargs)[source]
Bases:
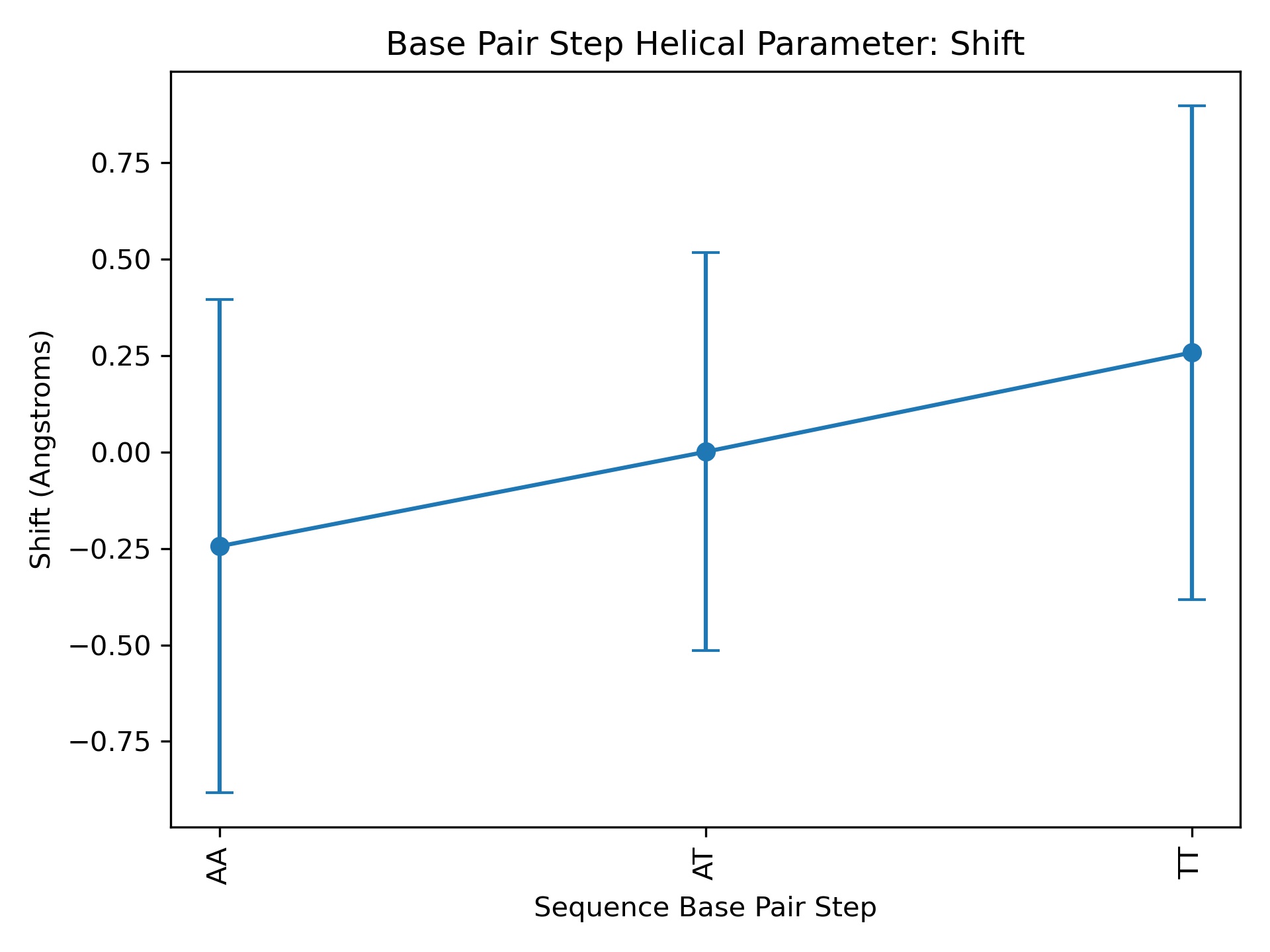
BiobbObjectbiobb_dna HelParAveragesLoad .ser file for a given helical parameter and read each column corresponding to a base calculating average over each one.Calculate average values for each base pair and save them in a .csv file.- Parameters:
input_ser_path (str) – Path to .ser file for helical parameter. File is expected to be a table, with the first column being an index and the rest the helical parameter values for each base/basepair. File type: input. Sample file. Accepted formats: ser (edam:format_2330).
output_csv_path (str) –
Path to .csv file where output is saved. File type: output. Sample file. Accepted formats: csv (edam:format_3752).
output_jpg_path (str) –
Path to .jpg file where output is saved. File type: output. Sample file. Accepted formats: jpg (edam:format_3579).
properties (dict) –
sequence (str) - (None) Nucleic acid sequence corresponding to the input .ser file. Length of sequence is expected to be the same as the total number of columns in the .ser file, minus the index column (even if later on a subset of columns is selected with the seqpos option).
helpar_name (str) - (Optional) helical parameter name.
stride (int) - (1000) granularity of the number of snapshots for plotting time series.
seqpos (list) - (None) list of sequence positions (columns indices starting by 0) to analyze. If not specified it will analyse the complete sequence.
remove_tmp (bool) - (True) [WF property] Remove temporal files.
restart (bool) - (False) [WF property] Do not execute if output files exist.
sandbox_path (str) - (“./”) [WF property] Parent path to the sandbox directory.
Examples
This is a use example of how to use the building block from Python:
from biobb_dna.dna.dna_averages import dna_averages prop = { 'helpar_name': 'twist', 'seqpos': [1,2], 'sequence': 'GCAT' } dna_averages( input_ser_path='/path/to/twist.ser', output_csv_path='/path/to/table/output.csv', output_jpg_path='/path/to/table/output.jpg', properties=prop)
- Info:
- wrapped_software:
name: In house
license: Apache-2.0
- ontology:
name: EDAM
schema: http://edamontology.org/EDAM.owl
{kind=link}
- dna.dna_averages.dna_averages(input_ser_path: str, output_csv_path: str, output_jpg_path: str, properties: dict | None = None, **kwargs) int[source]
Create
HelParAveragesclass and execute thelaunch()method.
dna.dna_timeseries module
Module containing the HelParTimeSeries class and the command line interface.
- class dna.dna_timeseries.HelParTimeSeries(input_ser_path, output_zip_path, properties=None, **kwargs)[source]
Bases:
BiobbObjectbiobb_dna HelParTimeSeriesCreated time series and histogram plots for each base pair from a helical parameter series file.The helical parameter series file is expected to be a table, with the first column being an index and the rest the helical parameter values for each base/basepair.- Parameters:
input_ser_path (str) –
Path to .ser file for helical parameter. File is expected to be a table, with the first column being an index and the rest the helical parameter values for each base/basepair. File type: input. Sample file. Accepted formats: ser (edam:format_2330).
output_zip_path (str) –
Path to output .zip files where data is saved. File type: output. Sample file. Accepted formats: zip (edam:format_3987).
properties (dict) –
sequence (str) - (None) Nucleic acid sequence corresponding to the input .ser file. Length of sequence is expected to be the same as the total number of columns in the .ser file, minus the index column (even if later on a subset of columns is selected with the usecols option).
bins (int) - (None) Bins for histogram. Parameter has same options as matplotlib.pyplot.hist.
helpar_name (str) - (None) Helical parameter name. It must match the name of the helical parameter in the .ser input file. Values: majd, majw, mind, minw, inclin, tip, xdisp, ydisp, shear, stretch, stagger, buckle, propel, opening, rise, roll, twist, shift, slide, tilt, alphaC, alphaW, betaC, betaW, gammaC, gammaW, deltaC, deltaW, epsilC, epsilW, zetaC, zetaW, chiC, chiW, phaseC, phaseW.
stride (int) - (1000) granularity of the number of snapshots for plotting time series.
seqpos (list) - (None) list of sequence positions (columns indices starting by 1) to analyze. If not specified it will analyse the complete sequence.
remove_tmp (bool) - (True) [WF property] Remove temporal files.
restart (bool) - (False) [WF property] Do not execute if output files exist.
sandbox_path (str) - (“./”) [WF property] Parent path to the sandbox directory.
Examples
This is a use example of how to use the building block from Python:
from biobb_dna.dna.dna_timeseries import dna_timeseries prop = { 'helpar_name': 'twist', 'seqpos': [1,2,3,4,5], 'sequence': 'GCAACGTGCTATGGAAGC', } dna_timeseries( input_ser_path='/path/to/twist.ser', output_zip_path='/path/to/output/file.zip' properties=prop)
- Info:
- wrapped_software:
name: In house
license: Apache-2.0
- ontology:
name: EDAM
schema: http://edamontology.org/EDAM.owl
- launch() int[source]
Execute the
HelParTimeSeriesobject.
- dna.dna_timeseries.dna_timeseries(input_ser_path: str, output_zip_path: str, properties: dict | None = None, **kwargs) int[source]
Create
HelParTimeSeriesclass and execute thelaunch()method.
dna.dna_timeseries_unzip module
Module containing the DnaTimeseriesUnzip class and the command line interface.
- class dna.dna_timeseries_unzip.DnaTimeseriesUnzip(input_zip_file, output_path_csv, output_path_jpg, output_list_path=None, properties=None, **kwargs)[source]
Bases:
BiobbObjectbiobb_dna DnaTimeseriesUnzipTool for extracting dna_timeseries output files.Unzips a zip file containing dna_timeseries output files and extracts the csv and jpg files.- Parameters:
input_zip_file (str) –
Zip file with dna_timeseries output files. File type: input. Sample file. Accepted formats: zip (edam:format_3987).
output_path_csv (str) –
dna_timeseries output csv file contained within input_zip_file. File type: output. Sample file. Accepted formats: csv (edam:format_3752).
output_path_jpg (str) –
dna_timeseries output jpg file contained within input_zip_file. File type: output. Sample file. Accepted formats: jpg (edam:format_3579).
output_list_path (str) (Optional) –
Text file with a list of all dna_timeseries output files contained within input_zip_file. File type: output. Sample file. Accepted formats: txt (edam:format_2330).
properties (dic) –
type (str) - (None) Type of analysis, series or histogram. Values: series, hist.
parameter (str) - (None) Type of parameter. Values: majd, majw, mind, minw, inclin, tip, xdisp, ydisp, shear, stretch, stagger, buckle, propel, opening, rise, roll, twist, shift, slide, tilt, alphaC, alphaW, betaC, betaW, gammaC, gammaW, deltaC, deltaW, epsilC, epsilW, zetaC, zetaW, chiC, chiW, phaseC, phaseW.
sequence (str) - (None) Nucleic acid sequence used for generating dna_timeseries output file.
index (int) - (1) Base pair index in the parameter ‘sequence’, starting from 1.
remove_tmp (bool) - (True) [WF property] Remove temporal files.
restart (bool) - (False) [WF property] Do not execute if output files exist.
sandbox_path (str) - (“./”) [WF property] Parent path to the sandbox directory.
Examples
This is a use example of how to use the building block from Python:
from biobb_dna.dna.dna_timeseries_unzip import dna_timeseries_unzip prop = { 'type': 'hist', 'parameter': 'shift', 'sequence': 'CGCGAATTCGCG', 'index': 5 } dna_timeseries_unzip( input_zip_file='/path/to/dna_timeseries/output.zip', output_path='/path/to/output.csv', output_list_path='/path/to/output.txt' properties=prop)
- Info:
- wrapped_software:
name: In house
license: Apache-2.0
- ontology:
name: EDAM
schema: http://edamontology.org/EDAM.owl
{kind=link}
dna.dna_bimodality module
Module containing the HelParBimodality class and the command line interface.
- class dna.dna_bimodality.HelParBimodality(input_csv_file, output_csv_path, output_jpg_path, input_zip_file=None, properties=None, **kwargs)[source]
Bases:
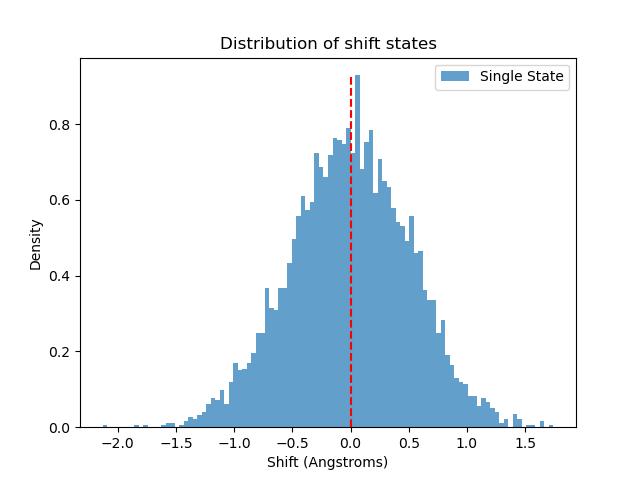
BiobbObjectbiobb_dna HelParBimodalityDetermine binormality/bimodality from a helical parameter series dataset.Determine binormality/bimodality from a helical parameter series dataset.- Parameters:
input_csv_file (str) –
Path to .csv file with helical parameter series. If input_zip_file is passed, this should be just the filename of the .csv file inside .zip. File type: input. Sample file. Accepted formats: csv (edam:format_3752).
input_zip_file (str) (Optional) – .zip file containing the input_csv_file .csv file. File type: input. Accepted formats: zip (edam:format_3987).
output_csv_path (str) –
Path to .csv file where output is saved. File type: output. Sample file. Accepted formats: csv (edam:format_3752).
output_jpg_path (str) –
Path to .jpg file where output is saved. File type: output. Sample file. Accepted formats: jpg (edam:format_3579).
properties (dict) –
helpar_name (str) - (Optional) helical parameter name.
confidence_level (float) - (5.0) Confidence level for Byes Factor test (in percentage).
max_iter (int) - (400) Number of maximum iterations for EM algorithm.
tol (float) - (1e-5) Tolerance value for EM algorithm.
remove_tmp (bool) - (True) [WF property] Remove temporal files.
restart (bool) - (False) [WF property] Do not execute if output files exist.
sandbox_path (str) - (“./”) [WF property] Parent path to the sandbox directory.1
Examples
This is a use example of how to use the building block from Python:
from biobb_dna.dna.dna_bimodality import dna_bimodality prop = { 'max_iter': 500, } dna_bimodality( input_csv_file='filename.csv', input_zip_file='/path/to/input.zip', output_csv_path='/path/to/output.csv', output_jpg_path='/path/to/output.jpg', properties=prop)
- Info:
- wrapped_software:
name: In house
license: Apache-2.0
- ontology:
name: EDAM
schema: http://edamontology.org/EDAM.owl
- fit_to_model(data)[source]
Fit data to Gaussian Mixture models. Return dictionary with distribution data.
- launch() int[source]
Execute the
HelParBimodalityobject.
{kind=link}
- dna.dna_bimodality.dna_bimodality(input_csv_file, output_csv_path, output_jpg_path, input_zip_file: str | None = None, properties: dict | None = None, **kwargs) int[source]
Create
HelParBimodalityclass and execute thelaunch()method.